14. The Memory Subsystem
Part of
CS:2630, Computer Organization Notes
|
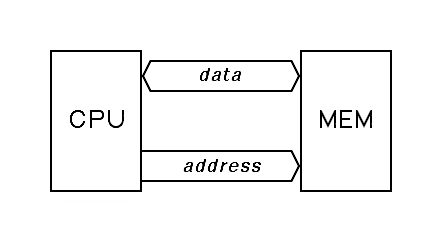
Up to here, we assumed a very simple model of main memory, where the address output by the processor goes straight to memory without change, and where the data path to and from memory is direct, as in this figure:
|
|
There are two problems with this model. First, a typical processor of the year 2000 could execute about 1 billion instructions per second, while typical memory of that year could handle only about 20 million memory references per second. Today's CPUs are much faster than memory! Processors designed with vacuum tubes in 1950, those designed with integrated circuits in 1965 or those designed as microprocessors in 1980 were about as fast as main memory. The naive model was no problem on those machines. By 1970, however, the fastest computers had CPUs that were significantly faster than main memory, and by 1980, and the difference has increased over the decades since then.
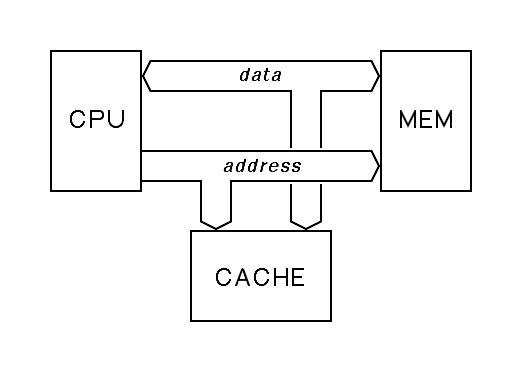
We solve this problem with a cache memory between the central processor and the main memory. Cache memory takes advantage of the fact that, with most memory technologies, we can build either large slow memories or small fast ones. This was known as far back as 1946, when Berks, Goldstine and VonNeumann proposed the use of a memory hierarchy, with a few fast registers in the CPU at the top of the hierarchy, a large main memory in the middle, a rotating magnetic drum memory below that, and a library of off-line data at the very bottom.
A cache memory sits between the CPU and the main memory. During each memory cycle, the cache checks the memory address issued by the CPU. If the address matches the address of one of the few memory locations held in the cache, the cache finishes the memory cycle quickly; this is called a cache hit. If the address does not match, the cache cannot help, so the slow memory must finish the cycle; this is called a cache miss. All cache systems implement some policy to determine which set of memory locations are held in fast memory inside the cache and when this set will change. This is called the cache replacement policy.
|
A cache constantly monitors the data and address busses between the CPU and main memory. This bus must be designed to allow such eavesdropping, and the memory must be designed to allow a cache to force premature completion of an otherwise slow memory cycle.
Given a small fast memory and a large slow one, programs could explicitly move data between them. Writing such code is hard. A cache automates this at the lowest levels. With the right trap handlers, an operating system can do this at higher levels. In 1962, Ferranti Ltd., working with Manchester University, figured out how on their Atlas computer, the first to incorporate what was later called a paged memory-management unit (MMU) and to support virtual memory. An alternate was developed by Burroughs Corporation around the same time, but modern computers tend to follow the paged model of Atlas.
By 1970, several commercial systems supported virtual memory and IBM was scrambling to support it. By 1985, such as the Intel 80386 and the Motorola 68030 had virtual memory. By 2000, virtual memory was almost universal save on very small microcontrollers.
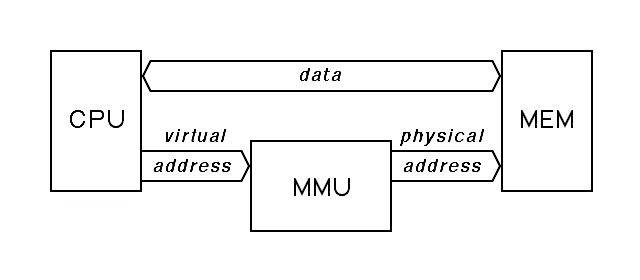
Put simply, virtual memory is present in any system where the memory addresses issued by the program are changed by any mechanism to produce the addresses delivered to memory. The mechanism that makes these changes has come to be called a memory-management unit, although it was known under other names in older systems.
|
Memory-management units take the address issued by the central processor and replace it with some other address, allowing the data that the current program is using to be stored in a relatively small main memory. So long as the program never only uses data in main memory, it runs at full speed. When it tries to use something that isn't there, the memory-management unit forces a trap. The trap handler in the operating system moves the required data to main memory from slow memory (usually disk). To do this, it typically has to move other data out of main memory to make room. This activity is called a page fault.
With the naive memory model, we spoke simply of the address of a word. Adding a memory-management unit forces us to distinguish between two kinds of address. The address output by the CPU to the memory-management unit is the virtual address, while the output of the memory-management unit is the physical address. The memory-management unit translates virtual addresses to physical addresses. Expanding on this, the virtual address space is the set of all virtual addresses a program can reference, while the physical address space is the set of all physical memory addresses. Both address spaces include values that may be illegal, virtual addresses with no corresponding physical address, and physical addresses with memory attached.
Some authors, mostly British, refer to a virtual address as a name while they reserve the word address for physical addresses. They describe programs as operating in terms of (numeric) names of variables, while the memory holds these variables in specific addresses. In these terms, the memory-management translates names to addresses, much as a village postman might have done back when letters were addressed to people and it was up to the postman to know where they lived. This leads to terms such as name space and address space.
Memory-management units were invented to automate data transfers between levels in the memory hierarchy, but they have a sometimes more important use. The MMU can be used to isolate different programs from each other. Prior to the development of MMUs, an erroneous or malicious program could corrupt data anywhere in memory. With a MMU, the operating system can arrange things so that programs can only touch the parts of memory they are authorized to use.
A third use for memory-management units is to allow older architectures with small address spaces to be connected to larger physical memories. An address space is the range of addresses that the system may use. Over and over since computers were invented, memory has grown cheap enough to allow physical memories larger than the designers of successful CPUs ever imagined. With the right MMU, a computer like the PDP-8, which had only a 12-bit virtual address, could be connected to a physical memory with a 15-bit address. Later, a PDP-11, with a 16-bit virtual address was routinely sold with a physical memory with an 18-bit address. Today's 32-bit processors are frequently use 34 or more bits to address memory. This allowed architectures to continue in use for decades after they would otherwise have been forced into obsolescence.
Typical modern computers contain multiple caches plus a
MMU. An instruction cache or I cache
speeds up the fetch phase of the fetch-execute cycle.
A data cache or D cache holds operands, speeding the
execute phase. Sometimes, instead
of separate I and D caches, these are combined into a single on-chip cache,
the L1 cache. In addition, a larger slower L2 cache
may be outside the CPU chip.
Some memory chips include built-in L3 caches.
The cache levels L1, L2, etc. are counted moving from the
processor toward memory.
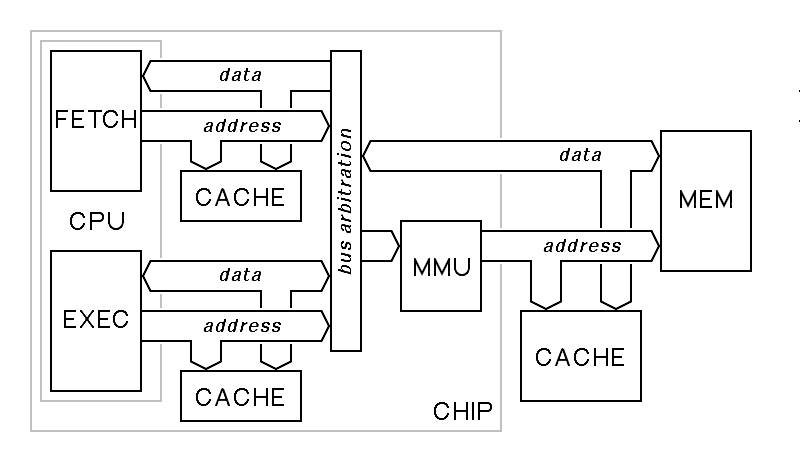
Thus, a complete system might be far more complex than that shown here:
|
In the above diagram, the CPU has two separate interfaces to memory, each with its own cache. Most modern processors are pipelined, so the next instruction is fetched while its predecessor is executed. If the execute phase of one instruction involves a load or store, the processor can do it in parallel with the instruction fetch so long as one or the other L1 cache has a hit. Only when both miss will the bus arbitration logic force the load or store to go first before the next instruction fetch.
Exercises
a) In the last figure above, identify the various caches according to type (I cache, D cache, L1 cache, L2 cache, L3 cache, etc). There may be multiple caches of one kind and none of some other kind. Also note that multiple names may be applicable to some of the caches.
b) In the last figure above, if the mapping performed by the memory-management unit is changed, the contents of some of the caches must be erased. Which ones? Why?
c) If an input/output device is connected to the memory bus, how could the cache cause problems? Hint: Consider the effect of a cache on polling loop testing a device-ready bit.
A simple cache can be built from a small, fast random-access memory plus auxiliary logic. The Hawk memory address space allows for a gigaword of memory with a 30 bit address. Consider accessing this through a 32 kiloword cache. This might be the L2 cache on a modern computer. Such a small memory can be much faster than main memory. If one memory cycle on main memory takes 50 nanoseconds, our L2 cache might have a 5 nanosecond cycle. Internal L1 caches might have cycle times of 0.5 nanoseconds in the same system.
One way to describe the function of a cache is in algorithmic terms, modeling each memory reference as a call to a cache function by the central processor. The cache access routines begin by searching the cache. If they find the desired data in the cache, they use it, while if they do not, they update the cache by accessing main memory, as described below:
unsigned int cache_tag[cachesize];
unsigned int cache_value[cachesize];
unsigned int cache_read( unsigned int address ) {
int i;
for (i = 0; i < cachesize; i++) {
if (cache_tag[i] == address) { /* hit */
return cache_value[i]
}
}
/* miss */
i = replacement_policy( 0, cachesize );
cache_tag[i] = address;
cahce_value[i] = RAM_read( address );
return cache_value[i];
}
void cache_write( unsigned int address, unsigned int value ) {
int i;
for (i = 0; i < cachesize; i++) {
if (cache_tag[i] == address) { /* hit */
cache_value[i] = value;
RAM_write( address, value );
return;
}
}
/* miss */
i = replacement_policy( 0, cachesize );
cache_tag[i] = address;
cache_value[i] = value;
RAM_write( address, value );
return;
}
|
The terms tag and value used above are traditional, not only in the context of cache memory, but in the context of all other forms of associative memory, whether implemented in hardware or software.
The above algorithmic description of a cache is correct, up to a point. This is what a cache does, not how it does it. The algorithmic description uses a sequential search to find cache hits where practical software implementations would use something faster. Using a faster algorithm here would only obscure the underlying function, and in any case, all modern cache hardware performs this search in parallel so it is very fast. Note that the replacement policy is completely unspecified. This policy determines what location in the cache is used when a new location is needed. The replacement policy has a big impact on performance.
Limiting the number of cache locations searched can have a big effect. For our 32K cache, consider what happens if we use 15 bits of our 30 bit main memory address to select a word in our small cache. This gives us no choice of replacement policy: For each particular word in main memory, there is exactly one word of cache that can be associated with it. At any instant, each word of the cache can be associated with just one of 32K different words in main memory, so we must store the other 15 bits of the memory address with that word to determine wich word in main memory it currently mirrors. This is called a set-associative cache because each word in the cache is associated with a different subset of words in main memory.
With this set-associative cache, each entry in our small cache must
hold a 15-bit tag along with the 32-bit cached word of data.
We declare a cache hit if the tag matches the corresponding address bits.
The design for this cache is in two halves, the data part that
actually stores addresses and tags, and the cache controller that
determines when the data part stores a value or delivers it to the bus.
The following diagram describes the data part of resulting hardware design,
using the low bits of the address to select
the cache line, that is, a particular word stored in the cache:
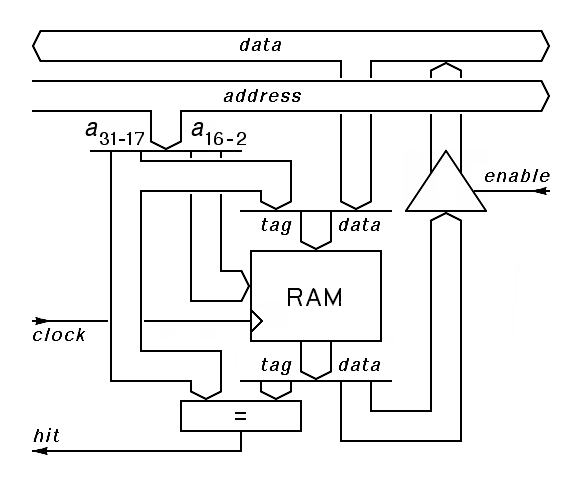
|
The logic shown here has one output to the cache controller, hit, indicating that the tag of the addressed word in the cache's memory matches the contents of the address bus. The cache controller for this cache must produce 2 control signals, clock, to indicate when a new data word and its tag should be stored by the cache, and enable to control when a data word from the cache should be put on the data bus.
The cache controller has two jobs. First, it must clock new data into the cache's internal memory whenever there is valid data on the data bus along with a valid address on the address bus. Second, when there is a hit during a read initiated by the processor, it must enable a transfer of the cache's data to the data bus, cutting the memory cycle short.
This cache design is called a write-through cache because it does nothing to accelerate write cycles. Write-back cahces are more complex, but the added benefit is not always worth the added complexity because the vast majority of all memory cycles initiated by the central processors are read operations. Write-back caches allow the CPU to continue as if a write to main memory had been completed as soon as the cache gets a copy of the value written. The cache is responsible for completing this write at a later time. As a result, the cache controller for a write-back cache must be able to initiate a write to memory independently of the CPU. The I cache that handles only instruction fetches need not support write cycles at all, and when a system has both L1 and L2 caches, it is fairly common for one of these to be a simple write-through cache.
The cache controller must connect with the bus control lines. For our first design, we will ignore write operations, as would be appropriate for the I-cache or for a cache used to speed access to a read-only memory. At minimum, the memory bus in this context requires two control lines, a read line that is asserted when the processor attempts to read from memory, and an ack line asserted by memory in response. The read signal indicates that a valid address is already on the address lines, and the ack line indicates that the data from memory is valid. The cache itself will assert the ack line when there is a cache hit. In this context, a working cache controller will look like this:
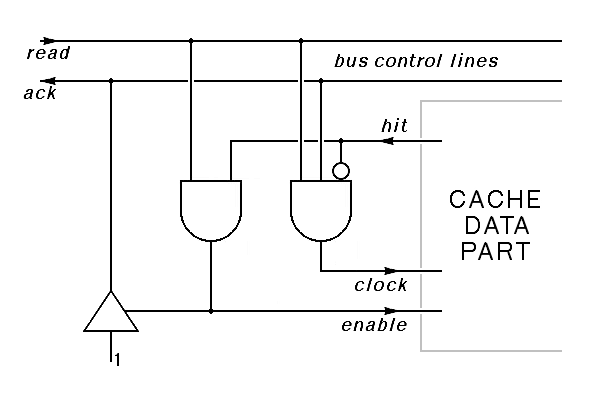
|
Note here that both the cache controller and the memory can drive the ack signal. If neither drives this signal, it is false. We show this using a bus driver on the cache controller; this driver provides no output if it is not enabled, and provides a constant output of one if it is enabled.
Extending this cache controller to make a write-through cache is not difficult. The primary new requirement is that the cache should record the value written whenever there is a write to memory. We need a new bus control line in this context. There are several alternative ways to do this. Consider useing the read line to indicate read cycles on the bus, and add a new line, write, that goes true when a valid address and the data to be written are both present on the bus. Since this is a write-through cache, the write logic never asserts the ack signal.
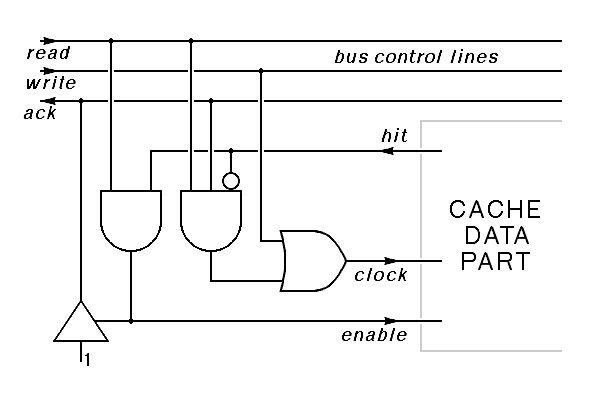
|
The cache controller and bus interface for a write-back cache
are more complex. Such a cache must sometimes initiate memory
cycles independently of the CPU, so a write-back cache controller
is really an independent but simple processor.
When the cache controller needs to write data back to RAM, it
initiates its own memory cycle, forcing the CPU to wait until the
cache is done with the bus before the CPU can continue
with whatever it was doing. As with direct-memory-access
input-output devices, this requires bus arbitrartion logic.
Exercises
d) The cache shown above will still work if the address lines are switched so that the most significant bits are used to select a word from the cache's memory and the least significant bits are stored as the tag. There would be no performance change if the addresses issued by the CPU were random. What is it about typical programs that makes this a bad choice?
e) The random access memory used in the cache shown here has a 15-bit memory address. How big is each word of this memory?
In the simplest virtual memory systems, the virtual address space is broken into fixed size pages, while the physical memory is broken into equal-sized page frames. In such a paged virtual memory, any page used by the CPU can be stored in any frame of physical memory, and the memory-management unit's job is to substitute the right frame number into the physical address when given a page number. That part of the address that indicates the particular byte in page or word in page is passed unchanged from virtual address to physical address.
the data structure used for this substitution is usually called either the page table or the memory map. We can describe the function of the memory-management unit using programming language notation as follows, assuming the integer data types physical_address and virtual_address:
constant unsigned int pagesize = (1 << bits_in_bytefield);
physical_address mmu( virtual_address va, memory_use use ) {
unsigned int address_in_page = va & (pagesize - 1);
unsigned int page_number = va >> bits_in_bytefield;
unsigned int frame_number = page_table[ page_number ].frame;
if (use > page_table[ page_number ].permission) throw BUS_TRAP;
return (frame_number << bits_in_bytefield) | address_in_page;
}
|
The simplest memory-management units store the entire page table inside a very small, very fast memory that is part of the memory-management unit itself. For example, the Digital Equipment Corporation PDP-11 had a virtual address that was 16 bits in length, and a physical address that was 18 bits in length. The first memory-management unit sold with this machine had a structure something like the following, although more complex:
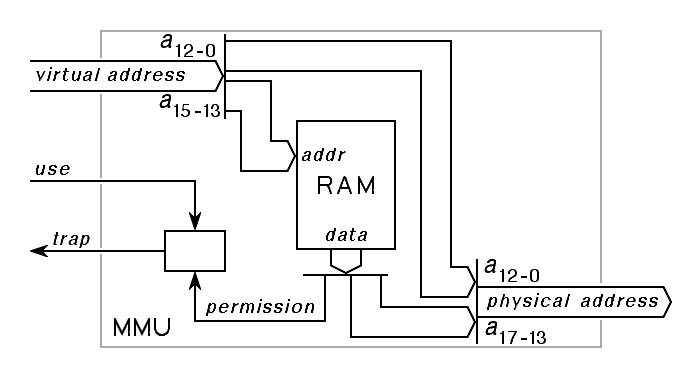
|
On the PDP-11, the top 3 bits of the 16-bit virtual address were used to select one of 8 entries in the page table inside the memory-management unit. The simplest way to use each page table entry was to use that entry to provided the top 5 bits of the 18-bit physical address. This solved two problems: First, it quadrupled the amount of main memory that could be attached to the machine, from 64K bytes to 256K bytes, and second, by changing the page table whenever the operating system switched from one running application to another, it allowed each application to have an independent protected memory address space of its own, thus controlling the damage that could be done by a malfunctioning application.
| ||||||||||||||||||||||||||||||||||||||||||||||||||
The term page is generally used when talking about the view of memory seen by the program. Thus, each virtual address contains three bits used to specify the page being addressed, with the lower bits of the address specifying the byte or word within that page. In contrast, when speaking about physical addresses, we generally use the term page frame or just frame to refer to a region of memory exactly big enough to hold one page of a program's address space. As a result, the fields of a physical address can be referred to as the frame field and the word-in-frame or byte-in-frame field.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Another detail shown in the diagram for the PDP-11 memory-management unit is a trap-request output from the memory-management unit to the central processor. The memory-management unit will request a trap if the use being made of a virtual address does not match the permissions associated with the page being referenced. Each page-table entry contains not only the frame number associated with the given page, but also the permissions or access rights for the page. When the central processor issues a memory address, it also indicates the use it intends to make of that address, for example, whether the processor intends a read or a write operation. The permission field of the page table indicates, for each page, what uses are permitted, and the trap logic inside the memory-management unit compares the use proposed with the permissions granted.
The operating system software is responsible for setting the access rights associated with each page. Pages containing variables must be marked read-write, while the pages containing instructions and constants are typically marked read-only. Some machines permit more subtle distinctions, for example, allowing pages that contain only instructions and no constants to be marked execute-only, pages containing only constants and not instructions to be marked read-only, and pages containing a mixture of instructions and constants to be marked read-execute. The closer the match between the access rights and the needs of the program, the sooner program malfunctions will be detected.
The figures given here do not show one detail: They do not hint at how the page table is loaded into the memory-management unit. On the PDP-11, the 8 registers holding the page table in the memory management unit were accessed as input-output device registers. The actual PDP-11 MMU was significantly more complex. Instead of the simple page table illustrated here, it had a segment table, where each segment was described by a base address and a size. As a result, the MMU had to add the base address to the virtual address instead of just substituting bits. To make things even more complex, PDP-11 segments could grow up or down from their base address. As memory grew less expensive, many PDP-11 operating systems ignored this complexity and used the MMU as if it was a purely paged MMU.
Exercises
f) The PDP-11 had byte addressing and a 16-bit word. Therefore, the virtual address has a word-in-page field and a byte-in-word field. Redraw the figures for the PDP-11 address layouts to show this detail.
g) How many bytes were there in a PDP-11 page, as described above.
h) The real PDP-11 memory-management unit did not divide the address space into fixed-size pages, but rather, into 8 variable-sized segments, where segments could be any number of 32-byte chunks in size, up to a maximum given by the size of the byte-in-segment field of the virtual address. Each segment could begin with any 32-byte chunk of physical memory, with the remainder of the segment occupying consecutive 32-bit chunks. Each page-table entry, therefore, contained the base address of a segment, in chunks, and the size of that segment, in chunks. Show the layout of the virtual and physical addresses.
i) Given the details given in the previous problem, how many bits are there in each segment-table entry? Give a possible layout for these bits.
j) Given the details given in the previous problems, plus the fact that the memory-management unit used an adder to add the chunk-in-segment field of the virtual address to the base-chunk-address from the page table, give a diagram for the data flow through the memory-management unit.
As mentioned above, the most elementary use of the memory-management unit is to provide each application that shares a computer with a separate virtual address space. As a result, no application is can address any memory other than that specifically given to it by the operating system. Without a memory-management unit, programming errors in an appliction can potentially damage other applications or the operating system itself, while with a memory-management unit, the consequences of programming errors or mailicious programs are strictly limited. As such, memory-management units are essential components secure and fault-tolerant computer systems.
Once the operating system has given each application its own address space, a number of things become possible. Each application can be given a virtual address space that appears entirely private, as if each application were running on a different computer, or the address spaces can be arranged to selectively share memory. It is the possibility of selective sharing of information that makes a single computer running multiple applications more interesting than a number of separate computers isolated from each other. To share a page between two virtual address spaces, we need to edit the page table entries for that page in each address space so that they refers to the same page frame. The contents of that frame will then be visible to both address spaces, as is the case with frames 5 and 6 shown in the figure below.
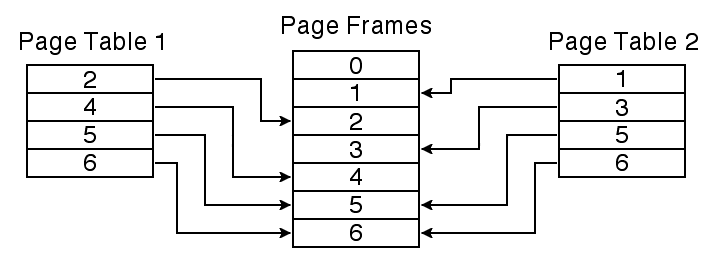
|
Use of a large physical address space on a machine with a small virtual
address space and control over information sharing were, historically speaking,
afterthoughts. The original reason for developing virtual memory and
mmory management units was to allow the operating system to create a large
fast virtual main memory using a small fast physical main memory combined
with a large slow memory such as a disk. The idea is old enough that
the first virtual memories used drum memory, so many of the key papers in
the field refer to paging drums.
The key to the success of this idea lies largely in how the operating system handles trap requests made by the MMU. At any particular time, most of the pages of the virtual address space are stored on disk, while only those pages currently being used are stored in page frames in main memory. When the program attempts to address a page that is not in main memory, the memory-management unit forces a trap, called a page fault. The page fault trap handler brings the required page from disk to main memory, probably moving some other page from main memory to disk, and then it returns, allowing the user program to continue.
This scheme is called demand-paged virtual memory because pages of the application program are transferred between main memory and disk on demand instead of being transferred in anticipation of demand. The detailed structure of a page-fault trap handler is typically discussed in elementary operating systems courses. In short, the page-fault trap handler must find a free frame in main memory, typically by evicting some page from main memory to disk, and then it must read the page needed by the application from disk into this free frame. Having done this, it must update the page table to reflect the new locations of each of these pages and then return to the application program.
This use of virtual memory requires that the trap hardware have one very specific property: When the memory-management unit requests a trap, the saved processor state must be the state immediately prior to fetching the instruction that caused the trap. Without this, the return from trap would not properly retry the instruction that caused the trap. If the hardware does not automatically save this state, it must be possible for the page-fault trap handler software to undo any side effects of a partially executed instruction. This can make it difficult to retrofit a machine for virtual memory that was not designed with that in mind.
Consider the question "how many times was the program counter incremented before the trap occurred?" On the Hawk, the answer depends on the opcode, and without knowing how many times the program counter was incremented, we cannot know which memory location contained the opcode for the instruction that caused the trap. On the Hawk, the hardware solves this problem for us by setting the TPC register to the address of the first halfword of the instruction that caused the trap.
There is a second problem. If all the page frames in RAM are currently in use, which page frame should be empitied so it can hold the page the user needed? This is determined by the trap handler's page replacement policy. As with cache replacement, the particular policy adopted can have a big effect on performance. The worst case is to replace the page that the program is about to use, perhaps on the very next instruction, while the best case is to replace that page that the program will not use for the longest possible time into the future.
Lacking a crystal ball for predicting the future, realistic page replacement policies must estimate the likelihood that pages will be needed in the future by looking at the history of use of each page. The best practical policy is to replace the page that was least recently used. An ideal cache memory would also use this policy to determine which words in the cache to replace. This policy, called LRU replacement, requires the memory-management unit (or cache) to maintain records of the most recent use of each page frame (or cache line). Most operating systems (and most caches) use approximations of LRU replacement, but occasionally, true LRU has been implemented.
Exercises
k) The Hawk memory-management unit records the address of the instruction that caused the trap into the TPC register. Suppose, instead, that it recorded the PC register at the instant of the trap. To allow demand-paged virtual memory under this new scheme, we can reserve a new field of the processor status word to hold how many times the program counter was incremented by the current instruction. First, how big would this field be on the Hawk, and second, what would the trap handler do with the value of this field.
l) The Hawk uses memory-mapped input-output. How can the memory-management unit be used to prevent an application program from directly accessing any input-output devices?
m) If the page table itself is stored in main memory, how can we use the memory-management unit to prevent application programs from changing the page table? Failure to do this would prevent virtual memory from being used to achieve any security goals.
The simple memory-management unit structure illustrated in the previous
section has one big
problem: It does not scale well. When the virtual address is only 16 bits,
with just 8 pages per address space, the very fast random
access memory inside the memory-management unit needs just 8 words.
Machines have been built using this approach with 256 pages in the virtual
address space, using an 8-bit page field.
We cannot scale this up indefinitely to millions of pages without
significantly slowing the memory-management unit.
Consider the layout of the bits
in a Hawk virtual address, a layout that is common on many modern 32-bit
processors.
| 31 | 30 | 29 | 28 | 27 | 26 | 25 | 24 | 23 | 22 | 21 | 20 | 19 | 18 | 17 | 16 | 15 | 14 | 13 | 12 | 11 | 10 | 09 | 08 | 07 | 06 | 05 | 04 | 03 | 02 | 01 | 00 |
| page | word in page | byte | |||||||||||||||||||||||||||||
Storing the page-table for this virtual address format inside the memory management unit would require that the small fast memory there contain 220 entries, about a million. Furthermore, loading a new page table into this memory would require updating all of these million entries, something we cannot afford to do each time the machine switches from one application to another.
The solution to this problem involves another cache. Instead of storing the entire page table within the memory-management unit, we only store that part of the page table relevant to the current program. For historical reasons, this special purpose cache is called a translation lookaside buffer, sometimes abbreviated TLB. So long as the program only uses page table entries that are already held in the translation lookaside buffer, the processor runs at full speed. When the program references a new page, however, we have what is called a TLB fault.
Remarkably, the memory-management units built in the 1960s and 1970s generally handled TLB faults entirely in hardware, stopping the execution of the program while the memory-management unit reached into a page table in main memory to update the contents of the translation lookaside buffer. This requires a memory-management unit controller with direct memory access and significant processing power, sometimes even an adder. It was only in the 1980s that the designers of what came to be called reduced-instruction-set-complexity architectures or RISC architectures discovered that it was quite reasonable to let software handle TLB faults.
Before digging into the details of the Hawk memory-management unit, note that the MMU of a computer may be turned off. When the computer is first started, the MMU is generally off, and it is up to the software to turn it on after the MMU is initialized and appropriate trap service routines are installed to catch any traps the MMU might request. In the case of the Hawk, the most significant bit of the level field of the processor status word, bit 31, determines whether the MMU unit is enabled. If this bit is one, the memory-management unit is active, while if it is zero, the memory-management unit is off and virtual addresses remain unchanged when they are delivered to memory.
Each field in the Hawk translation lookaside buffer consists of 45 bits, although we will always view this as two 32-bit words with a number of unused bits. Using cache memory terminology, the first word of each entry holds the tag, a 20-bit page number. The second word holds the associated data, a 20-bit frame number plus 5 access-control bits.
| 31 | 30 | 29 | 28 | 27 | 26 | 25 | 24 | 23 | 22 | 21 | 20 | 19 | 18 | 17 | 16 | 15 | 14 | 13 | 12 | 11 | 10 | 09 | 08 | 07 | 06 | 05 | 04 | 03 | 02 | 01 | 00 |
| page number | |||||||||||||||||||||||||||||||
| frame number | C | R | W | X | V | ||||||||||||||||||||||||||
If the page number issued by the central processing unit does not match the page number of any entry in the translation lookaside buffer, the memory management unit will request a trap. If the page number issued by the central processing unit matches some entry, the corresponding frame number is substituted into the address in order to create the physical address. The physical address is not used until the permissions from the TLB entry are checked against the use the processor is proposing. If the translation lookaside buffer entry is marked as invalid, or if the proposed operation on memory is not permitted, the memory-management unit forces the central processing unit to trap, aborting the execution of the current instruction.
|
Note that each translation lookaside buffer entry has one special bit, the cache enable bit C that determines whether results from any cache memory will be accepted. This bit should be set, by the operating system software, for all pages in memory that are stored in normal random access memory, but it should be reset for pages of the address space that reference device registers. When a program attempts to read from a device register, it wants the actual contents of that register and not something remembered from the past by a cache sitting between the central processor and the device.
We can describe the behavior of the Hawk MMU by an algorithm,
and as with the algorithms given earlier in this chapter,
we will use linear search where any real MMU hardware
would use fast parallel comparison. Note that the size of the Hawk
translation lookaside buffer, TLB_size in the following,
is hidden from the programmer. All the programmer needs to know is that
the translation lookaside buffer holds at least two entries and probably
more, and that each time the MMU requests a trap because of a TLB miss,
it must be given new entry it needs.
constant unsigned int bits_in_pagesize_field = 12;
constant unsigned int pagesize = 1 << bits_in_bytefield; /* 4096 */
physical_address mmu( virtual_address va; access_needed: rwxv ) {
int i;
unsigned int address_in_page = va & (pagesize - 1);
unsigned int page_number = va >> bits_in_bytefield;
for (i = 0; i < TLB_size; i++) {
if (TLB[i].page_number == page_number) { /* hit */
unsigned int frame_number = TLB[i].frame_number;
if ((TLB[i].access_control & rwxv) != rwxv) throw BUS_TRAP;
return (frame_number << bits_in_pagefield) | address_in_page;
}
}
/* miss */ throw BUS_TRAP;
}
|
When the memory-management unit requests a trap, it is reported to the operating system as a bus trap, which is to say, control is transferred to location 1016 and the memory-management unit is turned off because the level field of the processor status word is set to zero. The trap service routine for the bus trap can then determine the cause of the trap by examining the following resources:
MMUON = 27
When a trap occurs, the page number and word-in-page field of the virtual address that caused the trap are encoded here, along with a 2-bit indication of the condition that caused the trap in the least significant two bits that would usually hold byte in page. These bits take the following values:
TMANOTV = 0 ; invalid page, unimplemented memory
TMANOTX = 1 ; page not executable
TMANOTW = 2 ; page not writable
TMANOTR = 3 ; page not readable
The trap handler may write this register using CPUSET. Doing so places the contents of TMA and MMUDATA in some entry of the translation lookaside buffer. The software has no control over what entry is used, but there is a guarantee that the MMU will never contain more than one TLB entry for any particular page number. Each memory-management unit will implement some workable replacement policy. The following definitions will be used to reference the fields of this register:
MMUBITV = 0 ; valid bit
MMUBITX = 1 ; executable bit
MMUBITW = 2 ; writable bit
MMUBITR = 3 ; readable bit
MMUBITC = 4 ; cacheable bit
MMUSHIFT= 12 ; shift to align page frame number
After a bus trap, if the MMU was off (MMUON=0) the trap is unrecoverable. If the MMU was on, the trap handler must check the cause field of the TMA registe. If it is zero (TMANOTV), indicating an invalid address, but the valid bit (MMUBITV) of the MMUDATA register is one, then the physical address referred to nonexistant memory. If it was not valid, then the trap handler needs to look at the page table entry in RAM and, if it is valie, load it into the MMU data and address registers.
The design of the Hawk memory-management unit allows a trap handler written for a small memory-management unit with a crude replacement policy to continue working if the memory-management unit is upgraded with a big translation lookaside buffer and a good replacement policy. The trap handler never needs to know size of the translation lookaside buffer or the replacement policy being used. All that matters from the software perspective is that there are enough entries in the translation lookaside buffer to allow program execution, and that the memory-management unit hardware will not use the worst possible replacement policy.
The worst possible replacement policy would be to replace the most recently used entry in the translation lookaside buffer. In most cases, this entry will be the one that is most likely to be used next, since consecutive instructions are frequently executed from the same page. Either random replacement or first-in, first-out replacement would be better, but the best practical TLB replacement policy is the same one that works best with cache and demand paged virtual memory, that is, to replace the least recently used TLB entry. As with cache and virtual memory systems, typical hardware will only approximate this.
Exercises
n) On the Hawk, access to the page table used by the memory-management unit is through the CPUSET and CPUGET instructions. Why is it imortant to prevent applications programs from accessing these instructions?
o) Look at the algorithmic descriptions given for the cache-write function and for the Hawk memory-management unit and write a corresponding algorithmic description for the operation of writing the MMUDATA register. As with the cache-write function, you can assume a function called replacement-policy that handles that issue.
The simplest trap handler for the Hawk memory-management unit makes it appear as if the MMU translated addresses using a page table stored in RAM. This is sufficient for implementing a private address space for each user process and sharing of pages between address spaces, but a more complex handler is required for demand-paged virtual memory. These more complex handlers are the subject of extended discussions in operating systems courses.
We will assume that the page table is pointed to by a global variable, PAGETABLE, and we will assume that each page table entry is one word, in the format of the Hawk's MMU data register. The number of entries in the page table could potentially be 220, but most processes do not need that much memory. Therefore, we will use the first word in the PAGETABLE structure to hold the size of the table, in words, while the remainder is the actual table.
Our trap handler begins as outlined in the previous chapter, with code to save the trap registers. We will not repeat that code here, but will simply assume that all registers have been saved in the register save area pointed to by R2 as the body of our handler begins.
The first job the handler must do is examine the cause of the trap. Only when the MMU was turned on, and it reported an invalid address, and if the TLB entry used was indeed invalid, should the code try to update the MMU's translation lookaside buffer from the page table. If not, then this memory reference is an error and there is no point in attempting to update the TLB.
; see if the bus trap was caused by an MMU miss
LOAD R3,R2,PSWSAVE
BITTST R3,MMUON ; test high bit of old level
BBR NOTMIS ; if MMU off, not our problem!
CPUGET R3,TMA
TRUNC R3,2 ; test the 2 low bits of TMA
BZR NOTMIS ; if nonzero, not a TLB miss
CPUGET R3,MMUDATA
BITTEST R3,MMUBITV ; test the valid bit of TLB entry
BBS NOTMIS ; if nonzero, TLB entry valid,
; but it pointed to a bad frame
|
The label NOTMIS used above, should probably throw an exception on return from trap, using the logic given in the previous chapter. That code is not given here.
Once we have determined that the trap was caused by an MMU miss, the next step is to fetch the page table entry that needs to be stored in the TLB. To do this, we need to use the contents of the TMA register to index into the page table, after checking that the address is within bounds. If it is out of bounds, we go to NOTMIS to report an exception.
; get and check the page number field of the memory address
CPUGET R3,TMA
SRU R3,MMUSHIFT ; convert address to pagenum
LIL R4,PAGETABLE
LOADS R5,R4 ; get size of pagetable, in words
CMP R3,R5 ; check if it is within bounds
BGTU NOTMIS ; if out of bounds, not our problem!
; get page table entry
ADDSI R4,4 ; array starts after the table size
ADDSL R3,R4,2 ; compute address within page table
LOADS R3,R3 ; get page table entry
|
It is possible that the page table entry is invalid, in which case, we should handle this as an exception instead of updating the TLB. Thus, the final part of our handler begins with a validity check. The actual TLB update is done by setting the MMU data register. A side effect of this store operation takes the page field of the TMA register to build the full TLB entry.
; update TLB if page table entry is valid
BITTST R3,0 ; test valid bit in page table entry
BBR NOTMIS ; if not valid, don't update TLB
CPUSET R3,MMUDATA
JUMP TRAPEXIT ; return from trap
|
The above code uses the TRAPEXIT code defined in the previous chapter. In a real system, we would probably write streamlined code for both the bus trap entry and exit code in order to make TLB updates in the minimum possible time. The above trap handler code only needed registers R2 through R5, so a streamlined trap handler should not waste time saving or restoring registers R6 and up.
If the code for NOTMIS referenced above could throw an exception in the code that was running, but first, we face an important issue: What if the exception handler code itself was the cause of the trap? Simple-minded trap handlers sometimes throw the system into a tight loop in this case, but a well-written trap handler should prevent this. The details of how this is done depend on details outside the scope of this discussion.
Exercises
p) Assemble the pieces of a Hawk bus-trap trap handler from the previous chapter and this into a complete handler.
q) Optimize the handler you created for the problem above by eliminating all unneeded saving and restoring of registers. How many instructions are in the original, and how many in optimized version?
r) What is the correct value of the constant MMUSHIFT above?