22C:30, 22C:115 Project 2
Due date: Friday, 11/7, 5 pm
***UNDER HEAVY CONSTRUCTION***
Introduction
This project builds on Project 1.
The main difference between this project and Project 1 is that you will now
build a larger dictionary and will therefore have to use more sophisticated
data structures to provide efficient insertion and search.
This project will attempt to give you more practice building and using classes,
force you to use pointers, and introduce you to the hash table data structure.
Overview
As in Project 1, you will have to write two separate programs:
buildDict and spellCheck.
As in Project 1, the program buildDict builds a dictionary of words,
while the program spellCheck uses this dictionary
of words to determine which words in a given document are misspelled.
The program buildDict builds a dictionary by extracting
words from a document known to be free of spelling errors.
However, in this project, buildDict also keeps track of the frequency
of occurrence of each word that it extracts from the document.
When buildDict completes extracting all the words from the document,
it writes the extracted words onto a text file called words.dat.
In particular, buildDict starts by writing the 500 most frequent
words (in any order) into words.dat and then writes the remaining
words into words.dat in alphabetical order.
The spellCheck program reads words.dat and creates not one, but
two dictionaries: a primary dictionary containing the 500 most frequent
words and a secondary dictionary containing the remaining words.
The primary dictionary will be stored in a hash table data structure
while the secondary dictionary will be stored as before in a sorted Vector
of string objects.
A hash table is used for the primary dictionary because it provides almost
instantaneous search capabilities.
For each word in the document that is being checked for spelling errors,
the program spellCheck first consults the primary dictionary and if the
word is not found there, it consults the secondary dictionary.
The motivation for this two-level organization of the dictionary is that
many empirical studies have found that 80% of the words in an average document
come from a list of about 500 words!
Building a Dictionary
For this project I am making available a single compressed file called
novel.txt.gz (approximately 1300 Kbytes in size).
This file can be found in the directory:
~sriram/.public-html/17spring97/project2.
If you copy this file and uncompress it using gunzip you should get a text file
called novel.txt (approximately 3400 Kbytes in size).
I ran a Unix program called wc (short for ``word count'') on
novel.txt and found out that it has:
132734 lines, 602027 words, and 3412107 characters.
For this project, I want you to use the same definition of ``word'' as in Project 1.
Since this definition of a ``word'' is probably different from the Unix
definition of a ``word'' and since buildDict throws out duplicates
and certain other words, the number of distinct words that buildDict
extracts from novel.txt will be much less than 602027.
As before I want you to throw out words of length 1, but in addition I also
want you to throw out capitalized words that do not start a sentence.
A word is said to be capitalized, if its first letter is in
upper case and the rest of the letters are in lower case.
A word is said to begin a sentence, if the non-whitespace character immediately preceding
the first letter of the word is a period.
The reason for throwing out capitalized words that do not begin a sentence
is that such words are likely to be proper nouns.
It is possible that throwing out words as described above may not remove all proper
nouns and may in fact remove some words that are not proper nouns.
Data Structure used by buildDict
For this project buildDict needs to keep track of the frequency of
occurrence of the words it is extracting from novel.txt.
In particular, I want buildDict to maintain a list extracted words
that is sorted alphabetically as well as in non-increasing order of frequency.
In order to maintain a list of words that is simultaneously sorted by two keys,
I would like you to maintain two extra pieces of information corresponding to each word:
(a) the position of the word in the list of words sorted in alphabetical order and
(b) the position of the word in the list of words sorted in non-increasing order of frequency.
Thus, corresponding to each word, you will maintain three pieces of information:
frequency, alphabeticalPosition, and frequencyPosition.
Note that for the word that comes first in alphabetical order among the list
of words, alphabeticalPosition will be 1 and for the word with highest frequency
of occurring, frequencyPosition will be 1.
Thus the data structure that buildDict maintains can be thought of as a table
with four columns: word, frequency, frequencyPosition, and
alphabeticalPosition and as many rows as the number of words extracted.
Define a class called wordList that represents this data structure.
There are various ways of organizing the table described above,
but I want you to organize the data in the following manner.
Define a pointer:
row * myList;
in the private portion of the wordList class.
The class row that you see in the above definition represents each
row of the table.
Thus, each object belonging to class row contains 4 pieces
of information: word, frequency, frequencyPosition, and
alphabeticalPosition.
The member functions of the class row will be determined by how this
class is used by the wordList class.
Clearly, besides some number of constructors, the class row needs to provide certain
accessor member functions and also member functions to update values.
The member functions of the wordList class will be determined by how this
class is used by the buildDict program.
Besides a certain number of constructor functions, wordList might have to
provide member functions for inserting a word, searching for a word, updating
the frequencyPosition of words, and updating the alphabeticalPosition
of words.
I will leave the details of these functions to you and your program will be graded
based on the choices you make and how clearly you justify these choices in the
documentation you provide.
I hope you will not forget to provide copy constructors for these classes
and a destructor for the wordList class.
In keeping with our convention, you will define the row class in the files:
row.h and row.cc and the class wordList in
files: wordList.h and wordList.cc.
Inserting a word
As you know, the buildDict program repeatedly extract words from
the document novel.txt and attempts to insert them into an object
belonging to the wordList class.
Suppose that dictionary is the name of the wordList object
into which the extracted words are inserted.
In this section, I will give a brief overview of the task of inserting a
word into dictionary.
After buildDict extracts a word from the file novel.txt, it searches
(using binary search, since the words are in alphabetical order)
dictionary to see if the the newly extracted word already exists in dictionary.
If so, buildDict increments the frequency of this word.
This means that the position of the word in the list of words sorted by
frequency might change.
Thus buildDict will have to update frequencyPosition for some of the
words in dictionary.
You should do this as efficiently as possible and your program will be graded
based on the algorithm you use.
If the word extracted from novel.txt does not occur in dictionary, it
should be inserted into dictionary with its frequency set equal to 1.
This newly inserted word should therefore be last in the list of words sorted by
non-increasing frequency, but it can be anywhere in the list of words sorted in
alphabetical order.
Thus, as a result of inserting this new word, alphabeticalPosition of certain
words in dictionary might change.
You should make this change as efficiently as possible and your program will be graded
on the algorithm you use.
Writing output:
After buildDict finishes its task of extracting the words from novel.txt,
it has a list of words that are sorted in alphabetical order and are sorted
in non-increasing order of frequency.
The program buildDict should write these words into a file called words.dat.
The output should contain the 500 most frequent words first (in any order)
followed by the remaining words sorted in alphabetical order.
Each word should be written in a separate line.
The file words.dat will be read by the spellCheck program which
creates a primary dictionary for the first 500 words and a secondary dictionary
for the remaining words.
As stated earlier the primary dictionary is stored in a hash table and the secondary
dictionary is stored in a Vector of string objects sorted in alphabetical
order.
The spellCheck program
After the buildDict program completes its task and creates a dictionary file
words.dat, the spellCheck program is ready to take over.
This program starts by reading the first 500 words from the file words.dat
and stores then in a hash table.
This is the primary dictionary.
The hash table data structure will be described in the next section.
It then reads the remaining words from words.dat and stores them in a
list sorted in alphabetical order.
This is the secondary dictionary.
Then, as in Project 1, spellCheck sorts the words in the document it is spellchecking
and removes duplicates.
For each word in this resulting list, spellCheck searches the primary
dictionary first.
If the word is not found in the primary dictionary, spellCheck searches in the
secondary dictionary.
Any word not found in both dictionaries gets written to the file errors.dat.
So for the program spellCheck you will have to define two classes:
hashTable and sortedTable.
I will leave the task of designing these classes to you.
What is a hash table?
The idea of a hash table is simple.
Let U be the set of all possible strings of lower case letters.
Let  be a function that maps each string in U
to a number in the range 0 through M-1.
Then any subset
be a function that maps each string in U
to a number in the range 0 through M-1.
Then any subset 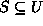 of strings can be stored in
a Vector called table of size M by storing
a string
of strings can be stored in
a Vector called table of size M by storing
a string 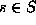 in slot
in slot 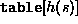 .
To determine whether a given string
.
To determine whether a given string 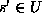 is also in S,
we simply compute
is also in S,
we simply compute 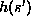 and determine if
and determine if 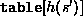 contains
contains 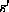 .
The only problem with this method is that there can be collisions
between strings.
For example suppose that for two distinct strings s and
.
The only problem with this method is that there can be collisions
between strings.
For example suppose that for two distinct strings s and 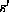 in S,
in S, 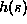 and
and
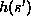 are both equal to some integer
are both equal to some integer 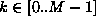 .
This means that both s and
.
This means that both s and  have to be stored in slot
have to be stored in slot 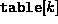 .
To handle such a situation, table should be defined not as a Vector
of string objects, but as a Vector of string pointers.
The only aspect of a hash table left to discuss is the hash function
h itself.
.
To handle such a situation, table should be defined not as a Vector
of string objects, but as a Vector of string pointers.
The only aspect of a hash table left to discuss is the hash function
h itself.
The following paragraph contains the definition of a possible hash function h.
Any string of lower case letters can be thought of as a number in base-26 by thinking of each
letter as the number obtained by subtracting 97 (the ASCII value of 'a') from the ASCII
value of the letter.
For example, the string next can be thought of as the following base-26 number: 13 4 23 19.
Thus a string  has an equivalent decimal value
has an equivalent decimal value 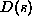 defined as:
defined as:
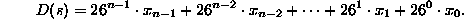
where 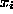 equals the ASCII value of
equals the ASCII value of 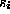 minus 97 for each i,
minus 97 for each i, 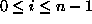 .
Now for any string S define a function
.
Now for any string S define a function 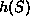 as follows:
as follows:

Thus the function h maps any string onto the range 0 though M-1.
The only thing left to decide is the value of M.
It is common practice to use a hash table whose size is approximately 10 times
the number of items being stored in it.
It is also common practice to choose the size of the hash table to be a prime number.
These two considerations led me to pick 5003 (the smallest prime larger than 5000) as
the value for M.
What (and when) to submit:
You are required to submit your work for this project in two parts.
The first part of the submission contains the files: buildDict.C,
row.h, row.cc, wordList.h, and wordList.cc.
These files essentially constitute the buildDict program.
These files need to be electronically submitted by 5 pm on Friday, 3/21.
The rest of the files ( spellCheck.C, hashTable.h, hashTable.cc,
sortedTable.h, and sortedTable.cc) that constitute the program
spellCheck are due by 5 pm on Monday 3/31.
As for Project 1 you should submit your files using the submit program.
A final word:
While I have specified quite a few details, I have left enough unspecified
so as to leave you with a few design decisions to make. These decisions will
affect the efficiency, robustness, and readability of your program.
So make your choices with care.
This project is more complicated than Project 1 along many dimensions. I suspect
it will take most of you all of three weeks; so please do not wait for two more
weeks to start!
In general the graders of your program will look for several things besides
the correctness of your program.
The overall organization of your program, the partitioning of various tasks
into functions, and program documentation will be taken into account while
grading.
Sriram Pemmaraju
Mon Mar 3 08:03:11 CST 1997