The Ultimate RISC
Part of
the Computer Architecture On-Line Collection
|
Reduced instruction set computer architectures have attracted considerable interest since 1980. The ultimate RISC architecture presented here is an extreme yet simple illustration of such an architecture. It has only one instruction, move memory to memory, yet it is useful.
This writeup is a revision of a paper by the same name published in ACM Computer Architecture News, 16, 3 (June 1988), pages 48-55.
A clear distinction has come to be recognized between two schools of instruction set design, frequently characterized as RISC, standing for reduced instruction set computer architecture and CISC, standing for complex instruction set computer architecture. In fact, the distinction between these schools emerged long before the names were coined. For example, this distinction is quite apparent in the comparison of the Data General Nova (RISC) and the DEC PDP-11 (CISC) architectures developed in the late 1960s.
The Nova has an instruction set in which most instructions can execute in a single fixed-length cycle involving an instruction fetch, and one of either a fetch, a store, or an operation on registers. In contrast, the PDP-11 has numerous addressing modes; depending on the mode, an instruction may execute in from 1 to 7 memory cycles. Both machines were designed in the late 1960s, and except for the RISC-CISC distinction, they are quite comparable; they competed for similar applications, offering similar performance at similar prices.
More recent machines characterizing this distinction are the Intel IAPX 432, and the Xerox Mesa machines (the Alto, Dorado and others) on the CISC side, and the IBM 801 (ancestor of the Power architecture), the Berkeley RISC (ancestor of the Sun SPARC), and the Stanford MIPS (ancestor of the processors SGI uses). In general, RISC machines are characterized by fixed format instructions and extensive use of pipelined execution, while CISC machines have variable length instructions and extensive use of microprogramming.
It is interesting to ask how far an instruction set can be reduced. It has been known for some time that a single instruction suffices, memory-to-memory subtract and branch if result negative. This is a complex instruction with 3 address fields (reducable to two if an accumulator is used), and the conditional branch phase of each instruction cycle depends on the results of the subtract phase of that instruction, inhibiting pipelined execution. Thus, although the `instruction set' contains only one instruction, that instruction does not conform to the RISC philosophy.
The Ultimate RISC `instruction set' presented here overcomes these problems. The only instruction in this set is a two address instruction that moves a single word from one memory location to another. The instruction execution unit of such a machine can hardly be considered to be a processor, since it performs no computations; thus, the term central processing unit is inappropriate here. If such a machine is to be useful, it must, of course, be able to compute; this problem can be solved by adding a memory mapped arithmetic unit.
This architecture is not intended to be a practical architecture. Surprisingly, however, the architecture can be made reasonably convenient with the addition of a small amount of extra hardware. For example, the attachment of a memory management unit between the instruction execution unit and the memory allows for indexing, and one additonal flipflop is enough to allow convenient conditional branches. Furthermore, this architecture may be pipelined, and doing this introduces all of the problems of instruction scheduling traditionally associated with RISC systems.
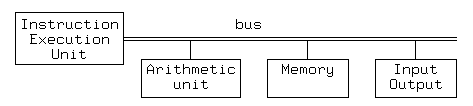
Figure 1A minimal implementation of the ulitmate RISC architecture requires an instruction execution unit, a memory, input-output devices, and a bus to connect these. Such a structure is outlined in Figure 1. The basic algorithm executed by the instruction execution unit is most easily expressed if a memory address fits exactly in a word. This has been assumed by the register transfer description of the instruction execution unit shown here:
registers pc, addr, temp;
repeat
1: addr := M[pc]; pc := pc + 1;
2: temp := M[addr];
3: addr := M[pc]; pc := pc + 1;
4: M[addr] := temp;
forever;
The instruction execution cycle for the minimal ultimate RISC requires
4 microcycles, each shown on a separate line above. Microcycle 1 fetches
the source address, cycle 2 fetches the operand, cycle 3 fetches the
destination address, and cycle 4 stores the operand. A much faster
implementation is possible using a pipelined instruction execution unit
and a 4 port memory.
The instruction execution unit described above has a drawback: There is no way to force a change in the program counter, and thus, no way to branch. This problem could be overcome by adding a second instruction for branching, but it is easier to simply make the program counter addressable as a memory location. Location zero is an obvious candidate for this function, but this is also an ideal place to put bootstrap code in ROM, so the topmost memory address is a better choice. Thus, moving a value to the topmost memory address will be used to cause a branch. Figure 2 shows the internal structure of an instruction execution unit able to execute the required register transfers with an extension to allow write-only addressing of the program counter.
Figure 2The control unit for the instruction execution unit shown in Figure 2 is quite simple both because there is no problem of opcode decoding and because there are no conditional operations in the instruction execution cycle. Figure 3 shows a timing diagram for the required control unit. The only point about this timing diagram that may not be obvious is that the PCMUX signal is held high during the write operation (microcycle 4) to allow address zero to write the program counter (note that there is no way to read the program counter). A control unit that produces the required waveforms needs only 16 states, or 4 states with a polyphase clock. In either case, the control unit requires 4 flipflops.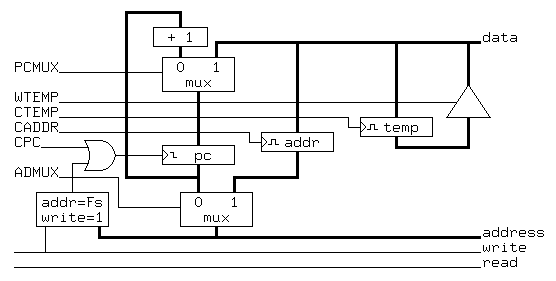
Figure 3Note that the waveforms given here as solid lines are quite conservative. In fact, CADDR and CPC could be the same, and WTEMP and write could be the same. The only reason we require that some of the control pulses be narrower than a full microcycle is to prevent multiple sources from briefly attempting to drive the data bus lines; we ensure this by bringing write and WTEMP solidly to false before read goes high. Aside from this constraint, the critical points in this waveform are the trailing edges of the clock pulses, which must come no later than the edges of the multiplexor controls.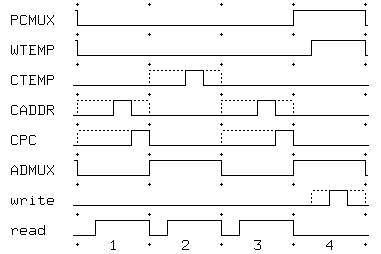
The utility of this instruction execution unit depends on the availability of an appropriate arithmetic unit. An example memory mapped arithmetic unit is for the ultimate RISC is shown in Figure 4. Note that most of the memory addresses that serve this arithmetic unit have two different meanings: When used as destination addresses, they store values in or operate on the accumulator; when used as source addresses, one address inspects the accumulator, and the others test condition codes.
Figure 4The arithmetic unit must allow loading and storing the accumulator, subtraction from the accumulator, and testing the sign of the result. The additional operations shown in Table 1 are optional (but very convenient). Write operations FFF1 through FFF6 can be directly computed by a 74LS351 ALU chip.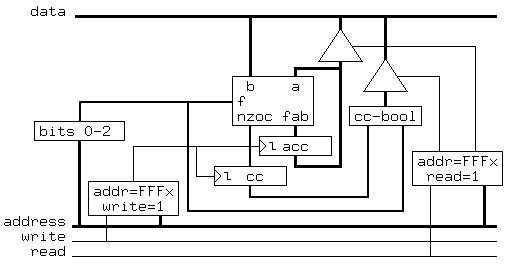
The condition code tests shown in Table 1 are based on those available on machines descended from the PDP-11, where N signifies a negative result, Z signifies a result of zero, O signifies a 2's complement overflow, and C signifies a carry out of the sign bit. The representation of Boolean values produced by the arithmetic unit is determined by the need to perform conditional branch instructions. True is represented by the value 2, and False is represented by zero. This is because an instruction occupies 2 words, and conditional branches are done by adding a boolean to a branch address.
Table 1: Arithmetic Unit Operations
address | write | read
----------+-----------------+--------------
FFF0 | acc = data | data = acc
FFF1 | acc = acc-data | data = N
----------+-----------------+--------------
FFF2 | acc = data-acc | data = Z
FFF3 | acc = data+acc | data = O
FFF4 | acc = data^acc | data = C
FFF5 | acc = data&acc | data = N^O
FFF6 | acc = data|acc | data = (N^O)|Z
FFF7 | acc = data>>1 | data = C^not(Z)
As an illustration of programming the minimal ultimate RISC, consider the problem of summing the contents of an array in memory. A high level outline of a solution to this problem follows;
variables ctr, ptr, sum;
sum := 0;
ptr := address( array );
ctr := size( array ) - 1;
repeat
sum := sum + ptr^;
ptr := ptr + 1;
ctr := ctr - 1;
until ctr < 0;
...
The SMAL
assembly language will be used to present the machine code that solves
this problem. In this language, the W assembly directive causes a word
to be assembled into memory, and most of the other details are borrowed
from the MACRO-11 assembler for the PDP-11 (VAX assembly language is very
similar). To simplify the coding, a macro will be defined that assembles
the two words of one machine instruction:
MACRO MOVE src, dst
W src
W dst
ENDMAC
In the assembly code, symbolic names will be used for the program counter,
accumulator, and other interfaces to the arithmetic unit:
pc = #FFFF ; dst only
acc = #FFF0 ; src or dst
sub = #FFF1 ; dst only
add = #FFF3 ; dst only
ccN = #FFF1 ; src only
ccZ = #FFF2 ; src only
Although no other definitions are necessary for programming the minimal
ultimate RISC, some operations are common enough to be worth their own
macros; these include load and store operations on the accumulator, and
instructions for adding, subtracting and branching, as defined below:
MACRO LDA src ; load acc
MOVE src, acc
ENDMAC
MACRO STA dst ; store acc
MOVE acc, dst
ENDMAC
MACRO ADD src ; add to acc
MOVE src, add
ENDMAC
MACRO SUB src ; subtract from acc
MOVE src, sub
ENDMAC
MACRO JMP dst ; jump indirect
MOVE dst, pc
ENDMAC
All operands in these macros are memory reference operands, but most
applications will require at least some immediate constants. A set of
macros can be used to hide the lack of an immediate addressing mode;
these rest on the following macro for storing immediate constants
relative to an alternate location counter:
COMMON immcom, immptr-immcom
immptr = immcom
MACRO IMMVAL val
immtemp = .
. = immptr
W val
immptr = .
. = immtemp
ENDMAC
Note that the COMMON n,s assembler directive causes the
allocation of a FORTRAN-like common block named n of size s.
As in MACRO-11, the period is used as a symbol for the assembly location
counter. As a result, the assignment directives .=immptr and
.=immtemp are interpreted as setting and resetting the assembly
origin. The following two macros allow immediate moves and immediate
versions of the single operand macros LDA, ADD, and
JMP:
MACRO MVI v, dst ;move immediate
MOVE immptr, dst
IMMVAL v
ENDMAC
MACRO IMM op, v ;immediate prefix
op immptr
IMMVAL v
ENDMAC
A final macro to simplify programming on the minimal ultimate RISC allows
conditional branching. This takes as operands the address of a Boolean
variable and the destination address, and jumps to the destination if the
Boolean is false or to the instruction after the destination if the Boolean
is true.
MACRO SKIP bool, lab
LDA bool
IMM ADD,lab
JMP acc
ENDMAC
A program for the minimal ultimate RISC that solves the problem of summing
an array can now be written:
MVI 0, total ;initialize
MVI array, ptr
MVI asize-1, count
loop: MOVE ptr, s ;modify LDA
s: LDA 0
ADD sum
STA sum
LDA ptr
IMM ADD,1
STA ptr
LDA count
IMM SUB,1
STA count
SKIP ccN, ex ;exit if neg
ex: IMM JMP,loop
In this program, the SKIP macro expands to 3 instructions, while the other
14 macros expand to one instruction each. Thus, this program takes 17
instructions of 2 words each. Immediate operands take another word each,
so the total storage required is 41 words. One pass through the loop body
involves 14 instructions or 56 memory cycles.
In contrast, the equivalent PDP-11 program using general registers and using the SOB (subtract one and branch) instruction for loop control can be written in 5 instructions occupying 7 words. In this case, the loop body is 2 instructions long and requires 3 memory references per iteration.
The above comparison clearly demonstrates that the minimal ultimate RISC architecture is not competitive, but it does not demonstrate that it is suboptimal! The class of optimal architectures can be thought of as a surface in a multidimensional computer design space. Taking typical axes of the space to be processor complexity (measured, for example, as the number of nand gates required to implement the processor, or the number of square millimeters of silicon needed under a fixed set of design rules), the program size for some benchmark, and the memory traffic required to execute that benchmark, it is clear that the PDP-11 is better than the minimal ultimate RISC on two axes, but it also requires a more complex processor. The minimal ultimate RISC can only be proven to be suboptimal if a processor can be found that is better when measured along at least one axis of the design space while being no worse along any other axes.
More information on move machines can be found at the TU Delft Move Project web pages. Interested readers should also investigate the Burroughs B 1700 and B 1800 microarchitectures from the late 1970's; these were not pure move machines, but they came very close to this model.
Another move machine is the ABLE; unlike the Burroughs machines, this was a pure move machine; like the Burroughs machines, the ABLE instruction set addresses memory indirectly through one of the registers in the CPU. As a result, the address spaces for source and destination fields on these machines is quite small, allowing reference only to the, ALU, I/O space, CPU control space and a modes register set, 16 words in the case of the ABLE.
Another move architecture was the GRI-909, made by GRI Computer Corporation of Newton Massachusetts in the late 1960s and early 1970s. GRI was founded by Saul Dinman, the designer of the PDP-8/S, after he left DEC. This was an impure move architecture, although, at the processor-memory-switch level it was extremely similar to the architecture proposed here. At the instruction-set-processor level, it was more complex; each 16-bit instruction had a 6-bit source, a 6-bit destination and a 4-bit function field; the presence of this function field and the approach this machine takes to memory addressing are far more complex than the approach discussed here, although they are still very simple compared to conventional instruction sets. As of May 2002, the reference manual for this machine is available on the web thanks to Al Kossow and an emulator is on the web at Bob Supnik's web site.
Sidenote: Saul Dinman explained in 2003 that GRI was originally General Research Corporation, a private Massachussetts company; when it went public, it had name conflicts with a pre-existing General Research, and then with General Radio as it hunted for a non-conflicting name. Under the name GRI, the company was eventually acquired by venture capitalists in North Carolina, and then by a display manufacturer that wanted to buy their OEM supplier, and finally by Analog Devices. The GRI processor architecture was one of the first bus-oriented architectures built using a printed-circuit backplane. Thousands of GRI-909 systems were sold on an OEM basis, mostly in the industrial control sector. Had marketing and capitalization worked out differently, the GRI-909 might have been an effective competitor for the Data General Nova, another DEC spinoff.
Some early drum machines, such as the British DEUCE computer, circa 1955, encoded the data part of their instruction set as a series of move instructions, but these machines typically also included a next-address field in each instruction, making them quite different from pure move machines.
Gene Styer has written an OISC simulator that includes several move machines, some of which are far more radical than the one proposed here (move memory to memory with a 16-bit address and an 8-bit data path lets you dispense with the ALU and replace it with lots of table lookups, reminiscent of the old IBM 1620 CADET). OISC, by the way, is an acronym for One Instruction Set Computer, a fairly new term for computers with no opcode field in their instructions. SISC, Single Instruction Set Computer, is an alternative acronym that is sometimes used, although it is sometimes a spoonerism of SCSI, with an entirely different meaning.
The Ultimate RISC proposed here went on to play an interesting role in later work by others. Steve Loughran formally defined, designed and built a 32-bit variant of this architecture as his final-year project at Edinburgh University in 1989. Since that time, several others have based various projects on this or similar architectures.
Adam Donlin has proposed using an Ultimate RISC as a host for a dynamically reconfigurable FPGA coprocessor in "Self Modifying Circuitry -- A Platform for Trackable Virtual Circuitry" in Proceedings of FPL the 9th International Workshop, FPL99, Springer-Verlag, ISSN 0302-9743, Aug 1999.
Paul Frenger wrote published a paper in ACM Sigplan Notices 35, 2 (Feb 2000) entitled "The Ultimate RISC: A Zero-Instruction Computer"; that paper had nothing at all to do with the work discussed here.
In late December 2021, Juergen Pintaske pointed me at Steve Teal's VHDL implementation of Juergen's MISC16 variant on the Ulitmate RISC. This has a slightly closer coupling between the move engine and the ALU, enough that you can just call the two of them a CPU, and it has been manufactured as an ASIC. An eForth interpreter has been written for it, so it can actually be used with an (arguably) high-level language. The whole project, including VHDL code, the eForth interpreter in assembly, a cross assembler writtein in Python and a C emulator for MISC16 is available on Github.
Some years after I wrote the Ultimate RISC paper, I realized that a far simpler but far slower Ultimate RISC is possible. My notes on this idea are dated 7 May 2003.
The idea is to replace the ALU with a very simple accumulator, where the address of the accumulator is 111111111111xxxx16, which is to say, only the top 12 bits of the accumulator address matter. The bottom 4 bits are used to determine which 4-bit fields of the accumulator are to be written or read.
On write, the other bits remain unchanged, while on read, the other bits are all set to zero:
| xxxx = 0000 | no op | |
| xxxx = 0011 | bits 0-7 only | LOWBYTE |
| xxxx = 1100 | bits 8-15 only | HIGHBYTE |
| xxxx = 1110 | bits 4-15 only | HIGH12 |
| xxxx = 0001 | bits 8-15 only | LOWNIBBLE |
| xxxx = 1111 | bits 0-15 | ALLBITS |
If TABLEA is the address of a word holding the table address, with the 8 least significant bits of the address all zero, while the accumulator initially contains an index into a one page table, we can load the address of a table entry into the accumulator with:
MOVE TABLEA, HIGHBYTE
MOVE ALLBITS, NEXT ; modify the next source field
NEXT: MOVE 0-0, ALLBITS ; source will be modified!
Note that the expression 0-0 has the value zero, but this value is irrelevant. This is an antique idiom used to indicate a filler value that will be changed at run time by self-modifying code.
With this mechanism, all we need to do is pre-load several pages of memory with tables. For example, a table of sums of the two 4-bit nibbles making up the table address, and a table that maps 8-bit values to the corresponding values with the two 4-bit nibbles swapped. Given these two tables, adding two 4-bit numbers from memory and returning their 4-bit sum to one memory location and the carry out to another location takes only 13 instructions.
Clearly, an ALU leads to higher performance, but this alternative to an ALU takes only 16 flipflops, a 12-input and gate to decode the address, and 8 and gates to control which flipflops are read and written. That is far simpler than an adder.