Lecture 15, Attributes of Nonterminals
Part of
the notes for CS:4980:1
|
BNF gives a formal specification of syntax, but it does not specify semantics. Through the 1960s and into the 1970s, one thrust of computer science was to find a way of giving an equally formal specification to the semantics of programming languages. Attribute grammars were an early attempt to do this. The motivation for this is easy to see in a grammar for expressions. Consider this fragment of the Kestrel grammar:
<expression> ::= <comparand> [ <comparing operator> <comperand> ]
<comparand> ::= <term> { <adding operator> <term> }
<term> ::= <factor> { <multiplying operator> <factor> }
<factor> ::= [ "-" | "~" ] <value>
<value> ::= <number>
| <string constant>
| "null"
| <reference>
| <subexpression>
<subexpression> ::= "(" <expression> ")"
| "[" <expression> "]"
| "{" <expression> "}"
<reference> ::= <identifier>
| <reference> "@"
| <reference> "." <identifier>
| <reference> <expression list>
First, consider a simplified grammar, with this rule substituted for the corresponding rule above:
<factor> ::= [ "-" | "~" ] ( <number> | <string> | <subexpression> )
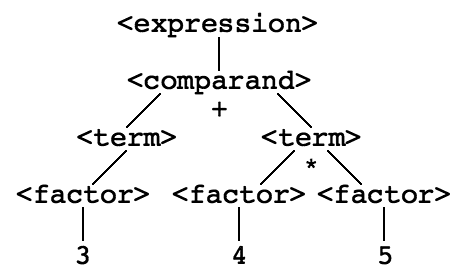
With this simplification, we eliminate the possibility of expressions that reference variables or other defined symbols. As a consequence, expressions are strictly constant-valued. In this case, if we look at the parse tree for an expression, we see data flowing up the tree from the leaves to the root. Consider this expression:
3 + 4 * 5
The parse tree for this expression is as follows:
We typically evaluate expressions by associating a value with each factor, term and other sub-expression, and then combining those values using the operators in the expression. In terms of the parse tree, this involves propagation of values from the leaves up the tree, combining those values at each level in the tree under the control of the operators at each level, as illustrated here:
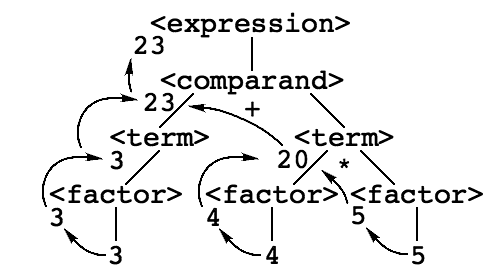
This basic idea has been formalized. In an attribute grammar, each terminal and nonterminal symbol in the language is annotated with a set of attributes, and each production rule is annotated with a mathematical description of how that rule processes the attributes with which it interacts. The simple notion that attributes merely flow up the tree is, however, insufficient. Consider what happens when we add variables back into the language:
<factor> ::= [ "-" | "~" ] ( <number> | <string> | <subexpression> | <reference> )
Now, the terms in expressions may include both constants (numbers and strings) and also identifiers. The bindings of identifiers to values must now be considered as flowing down the parse tree to the leaves. This set of bindings is ignored in those leaves that are simple numbers or strings, literal constants, but where there is an identifier, the leaf must find the value to which the identifier is bound.
One of the most important data structures in any compiler is the data structure that relates identifiers to their attributes. In fully developed programming languages, identifiers may name procedures and functions, they may name data types, they may name variables, or they may name constants. Procedures and functions are characterized by the number and types of their arguments, and variables and constants have types. Finally, constants have values and variables are associated with memory addresses.
The data structure within the compiler that binds identifiers to their attributes has been called by many names; we will refer to it here as the environment. When the compiler processes a declaration, it adds bindings of identifiers to attributes to the environment. When the compiler encounters an identifier while it is processing an expression, it looks up the attributes of the identifier in the environment.
Formally speaking, we can think of the environment as a function e that maps identifiers to their attributes. Given an identifier i, therefore, e(i) gives the attributes of i. For now, we'll only concern ourselves with one attribute, the value of the expression, but in the more general case, we could think in terms of identifier types, values of constants, memory addresses of variables and other more complex attributes.
The developers of attribute grammars spoke of two kinds of attributes associated with each nonterminal in the language, down attributes or inherited attributes that flow down the parse tree toward the leaves, and up attributes or generated attributes or return attributes that flow up the tree toward the roots. The typical notation that emerged was something like this:
<expression> e↓ v↑
This means that expressions pass the environment e down the parse tree and return a value v up the tree. Consider this production rule from our grammar:
<comparand> ::= <term> { <adding operator> <term> }
In an attribute grammar, this would typically be expanded as follows:
<comparand> e↓ v↑ ::= <term> e↓ v↑
<comparand> e↓ v1↑
::= <comparand> e↓ v2↑
"+" <term> e↓ v3↑
where v1 = v2 + v3
<comparand> e↓ v1↑
::= <comparand> e↓ v2↑
"-" <term> e↓ v3↑
where v1 = v2 – v3
In the above rules, the environment is simply passed down the tree, without either inspection or alteration, but in general, attribute grammars may inspect and alter any attributes being passed in any direction. Here is part of the rule for factors:
<factor> e↓ v↑
::= <number>
where v = value( <number> )
<factor> e↓ v↑
::= <identifier>
where v = e(<identifier>)
In the first rule above, the environment passed down to the leaf of the parse tree is ignored and the value of the number is returned up the tree. In the second rule, the environment is used. Here, we have interpreted the environment as a function which, when applied to an identifier returns the associated value. This works for identifiers that bind constant values to identifiers, but we need a more complex model to deal with variables in a programming language.
Attribute grammars get messy as the number of attributes rises, and there is always the awful possibility of cycles where some attribute just ends up circulating without ever being properly defined. This led to some work on automatic checking of attribute grammars to detect cycles, but the eventual resolution came from a different direction.
In parallel with the development of attribute grammars, a second school of thinking developed. This school was more worried about theory, so their work was founded on top of work in formal algebra that dated back to the work of Alonzo Church in the first half of the 20th century. To understand their work, you have to understand one of Church's great ideas, the lambda calculus.
The familiar mathematical notation for functions suffers from an important limitation. Consider this fuction:
succ(i) = i + 1
Most mathematics works quite well defining functions this way. Having defined the successor function succ, we can talk about the successor of a number. For example,
succ(5) = 5 + 1 = 6
The problem is, how do we speak of functions that return values that are themselves functions. That is, how do we deal with functions as first-class objects, the way our conventional functions deal with numbers as first-class objects. Can we write functions that compose other functions to create new functions?
Church proposed a notation, lambda notation, that allows us to at least describe such things. In lambda notation, we can define our successor function as follows:
succ = λ i . i + 1
In the lambda notation, the Greek letter λ (lambda) introduces an expression (a lambda expression) the value of which is a function. The identifiers between the letter lambda and the following dot are the names of arguments to that function, while the expression after the dot gives the value of the function. Here is a second (and more complex) example:
twice = λ f . λ i . f( f( i ) )
In English, the function twice takes an argument f (which must itself be a function) and returns a function of one variable i. That function applies f to the result of applying f to i. That is, it creates a new function that doubles the application of f. For examplke:
twice( succ ) = λ i . succ( succ( i ) )
That is, twice( succ ) constructs a function that computes i+2 by doubling the computation of i+1.
From a formal mathematical perspective, the lambda calculus opened up a can of worms by raising one simple question: What is the domain of this calculus? Lambda expressions are functions that can be applied to functions, so the set of all lambda expressions includes functions that take lambda expressions as arguments and return lambda expressions as values. It did not take people long to prove that there is an equivalence between lambda expressions and Turing machines, and that the set of lambda expressions includes all computable functions from lambda expressions to lambda expressions. Unfortunately, this quickly led set theorists to call a foul. Sets containing functions from that set to that set are inadmissable in classical set theory, so set theorists declared that lambda calculus is merely a formal notation with no admissible mathematical interpretation. In short, there is no such set. Of course, as computer science developed, computer scientists quickly realized that lambda calculus exactly captures what we are trying to do.
Denotational semantics attempts to build a formal algebraic model of the semantics of computer programs, and this model rests on lambda notation. It was only after this idea was largely worked out by Dana Scott and Christopher Strachey that it was shown to be exactly equivalent to attribute grammars, or at least, to well-formed attribute grammars that didn't have undefined cycles hiding in them. The attribute grammar interpretation of denotational semantics is as follows:
Attributes flow only upward in the parse tree. Where attributes would have flowed down the tree, the denotational equivalent instead has functions that flow up, where the down-flowing attributes are, ultimately, the arguments to the functions. Thus, for our grammar over expressions, we work as follows:
<comparand> v↑ ::= <term> v↑
<comparand> v1↑
::= <comparand> v2↑
"+" <term> v3↑
where v1
= λ e . v2( e
)+v3( e )
<comparand> v1↑
::= <comparand> v2↑
"-" <term> v3↑
where v1
= λ e . v2( e
)–v3( e )
Note that we don't need the up arrows anymore, because we have eliminated the down arrows, with all attributes flowing upwart toward the root of the tree. Continuing the example, here is part of the rule for factors:
<factor> v↑
::= <number>
where v
= λ e . value( <number> )
<factor> v↑
::= <identifier>
where v
= λ e . e( <identifier> )
In the first rule above, the value of a number is expressed as a lambda expression because we were forced to pass a function up the tree regardless of wheter we needed its argument. In this case, the value of the function only depends on the value of the number itself and the environment is ignored. In the second case, however, the function passed up the tree is one which, when eventually evaluated, will look up the identifier in the environment in order to get its value.
The work described above was motivated by work on formal semantics, not compiler construction. Furthermore, we simplified things, eliminating in the descriptions above any mention of run-time behavior. The description of expression semantics given above, for example, only applies to an environment containing constant definitions. Too speak of expressions that involve variables and run-time, as opposed to compile-time evaluation, we would have to have added a level of functions, where one set of functions represents compile-time computation, and the final result of the compilation is a second set of functions representing the run-time semantics of the compiled program.
What is more important here is the simple emphasis on the idea that each nonterminal in the grammar has associated with it a set of attributes. This idea is directly applicable to compiler construction, and in fact, working out the appropriate sets of attributes for each nonterminal is a key part of the move from merely parsing the syntax of a programming language and processing its semantics.